注:由于tensorflow版本的不同,这个函数所在的模块可能不同,如:tf.nn.seq2seq.sequence_loss_by_example和tf.contrib.legacy_seq2seq.sequence_loss_by_example
在正式进入sequence_loss_by_example()函数的计算过程之前,需要先复习下两个基本的知识点,softmax的计算和交叉熵的计算。
1 softmax的计算过程
可以直接网上已经写好的博客:三分钟带你对 Softmax 划重点,这篇文章中有举具体的例子,最好自己动手算一下,不自己动手计算,往往看了就忘了。
2 交叉熵的计算过程
交叉熵网上的文章也很多,一文搞懂交叉熵在机器学习中的使用,透彻理解交叉熵背后的直觉这篇文章讲得非常详细,还举了各种例子。
以上复习了softmax和交叉熵的计算过程,为啥要使用softmax和交叉熵,可以自行网上搜搜。接下来就进入sequence_loss_by_example()函数的计算过程。
3 sequence_loss_by_example()函数的计算过程(以TF的ptb构建语言模型例子为例)
注:例子中的batch_size=20,num_steps=20,为了更直观的查看各个数据的维度,我将num_steps改为了15.(因为本例是通过上一个词预测下一个词,其实num_steps改为多少并没有影响)。
(1)LSTM的输出
LSTM的隐藏层的单元个数为200,因此,LSTM每一步的输出数据的维度为(batch_size,hidden_size)。有因为LSTM展开的时间步数为num_steps,于是通过
outputs.append(cell_output)
将每一时刻的输出都收集起来,这样,最后的outputs是一个list,其样式为: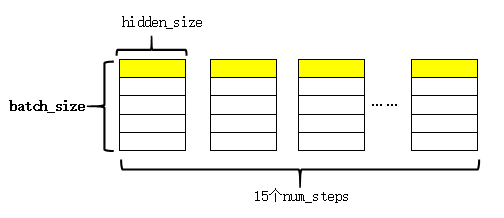
图中黄色的部分表示同一个序列在LSTM不同时刻的输出。
紧接着对outputs进行拼接和reshape,其过程如下图: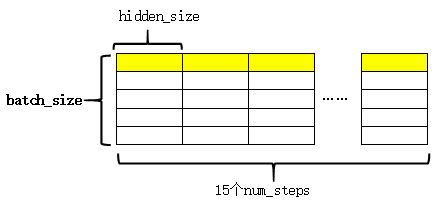
将每一时刻的输出在第1维上拼接(上图),这样每一行就完整的表示了一个序列。reshape后的结构如下图: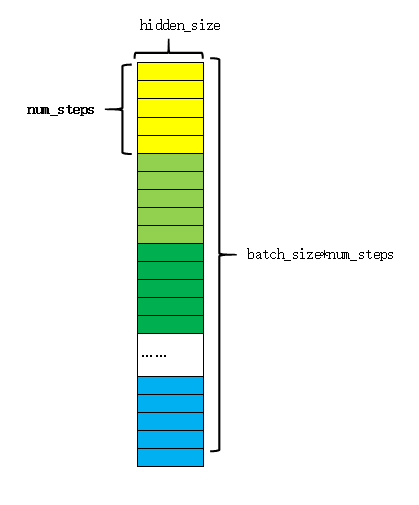
其中每一种颜色表示一个序列,同一种颜色中的各个块表示这个序列的不同时刻。
以上就是LSTM的输出,并对其适当变形。接下来通过一个全连接层,将每一时刻的输出映射成字典大小。
(2)通过全连接层
这部分就是常见的y=wx+b的构造形式,通过以下代码实现:
softmax_w = tf.get_variable( "softmax_w", [size, vocab_size], dtype=tf.float32)
softmax_b = tf.get_variable("softmax_b", [vocab_size], dtype=tf.float32)
# 网络的最后输出(相当于最后添加了一个全连接层)
logits = tf.matmul(output, softmax_w) + softmax_b # logits shape:batch_size*num_step,vocab_size
通过全连接层后,得到logits,其维度为(batch_sizenum_step,vocab_size),在本例中就是30010000(本例的词汇表大小是10000)。
(3)执行tf.contrib.legacy_seq2seq.sequence_loss_by_example函数
关于这个函数的定义,解释之类的,可以参考这个解释,小例子可以参考这个。前一篇博客的解释看得有些稀里糊涂的,后面就找了后面那个例子来跑跑,但是这两个都没有讲清楚内部是怎么计算的,后面我又参考了tensorflow的损失函数源代码,找到这个函数,可以看到这个函数在内部调用的是sparse_softmax_cross_entropy_with_logits()函数,好嘛,接下来就一步一步的来看整个计算过程。
首先来看输入的数据: logits和targets
- logits数据的格式在前面已经介绍了,为(30010000)的矩阵,300为num_stepsbatch_size得到,10000为词汇表大小,这个数据表示的意思是:每一行表示一个时刻(对应一个预测的单词),每num_steps行对应一个序列,一共有batch_size个num_steps行(因为这是一个batch大小的数据)。
- 输出targets的维度可以看到其形状为(batch_size,num_steps)(即2015),表示的意思是,一个batch中有20条数据,而每一条数据有15个时间步,一个时间步对应一个单词。为了让预测的单词的顺序和targets中真实单词的顺序对应上,于是将targets的维度变成了(300,)(即:2015),这样一个元素对应logits中的一行,每15个数据就表示一个序列。
接下来,就将上面的输入以及权重w(通常设置为1)传入sequence_loss_by_example函数。下面是这个函数的实现代码:
def sequence_loss_by_example(logits, targets, weights,
average_across_timesteps=True,
softmax_loss_function=None, name=None):
#logits: List of 2D Tensors of shape [batch_size x num_decoder_symbols].
#targets: List of 1D batch-sized int32 Tensors of the same length as logits.
#weights: List of 1D batch-sized float-Tensors of the same length as logits.
#return:log_pers 形状是 [batch_size].
for logit, target, weight in zip(logits, targets, weights):
if softmax_loss_function is None:
# TODO(irving,ebrevdo): This reshape is needed because
# sequence_loss_by_example is called with scalars sometimes, which
# violates our general scalar strictness policy.
target = array_ops.reshape(target, [-1])
crossent = nn_ops.sparse_softmax_cross_entropy_with_logits(
logit, target)
else:
crossent = softmax_loss_function(logit, target)
log_perp_list.append(crossent * weight)
log_perps = math_ops.add_n(log_perp_list)
if average_across_timesteps:
total_size = math_ops.add_n(weights)
total_size += 1e-12 # Just to avoid division by 0 for all-0 weights.
log_perps /= total_size
return log_perps
可以看到函数内部主要是调用sparse_softmax_cross_entropy_with_logits函数,然后再加权平均后返回。
那么这个sparse_softmax_cross_entropy_with_logits函数是怎么计算的呢?这里有个小例子,可以看到他是将softmax和cross_entropy放在一起计算,这里就涉及到文章开头所复习得softmax和交叉熵的计算过程了。
于是,我们知道了,针对于一个logits元素和一个targets元素,比如这个例子中取logits[0],其维度为(10000,),targets[0],它就是单独的一个整型的数,表示单词在词汇表中的id号。先计算logits[0]中各个元素的相对概率(即计算softmax),然后利用交叉熵公式计算预测值和真实值之间的交叉熵。
这个函数直接使用标签数据的,而不是采用one-hot编码形式(另一个函数softmax_cross_entropy_with_logits必须是one-hot形式的数据,具体见softmax_cross_entropy_with_logits函数详解)
为了验证这个计算过程,我将这个例子中的logits[0],targets[0]以及通过
loss = tf.contrib.legacy_seq2seq.sequence_loss_by_example( # 这个函数先求解softmax,再求解交叉熵
[logits],
[tf.reshape(input_.targets, [-1])],
[tf.ones([batch_size * num_steps], dtype=tf.float32)])
得到的loss(这里取loss[0])取出,单独通过tf.nn.softmax以及交叉熵公式来依存计算这个过程。
首先来看下通过例子源代码取出的数据情况:
logits shape:
(10000,)
logits value:
[ 7.8470936 8.238499 8.979608 ... -0.73421586 -0.913356
-0.7552418 ]
target value:
9971
loss value:
11.060587
自己计算的代码为:
import tensorflow as tf
# 将单词id转化为one-hot模式
target=list([0]*10000)
target[9971]=1
target=np.array(target)
# 转化为张量
logits=tf.convert_to_tensor(r['logits'],dtype=float)
y_=tf.convert_to_tensor(target,dtype=float)
# 法1,分开计算----------------------------------------------------
# 计算softmax
y=tf.nn.softmax(logits)
# 计算交叉熵
cross_entropy=-tf.reduce_sum(y_*tf.log(y))
# 法2,调用函数计算-------------------------------------------------
# 调用函数计算
cross_entropy2=tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(logits=logits,labels=y_))
with tf.Session() as sess:
softmax=sess.run(y)
c_e=sess.run(cross_entropy)
c_e2=sess.run(cross_entropy2)
print("softmax:\n",softmax)
print("cross_entropy:\n",c_e)
print("function:\n",c_e2)
运行结果为:
softmax:
[5.8356632e-02 8.6312823e-02 1.8110682e-01 ... 1.0946491e-05 9.1511438e-06
1.0718737e-05]
cross_entropy:
11.060587
function:
11.060587
可以看到,不管是分开计算还是调用函数计算,其结果和例子源代码中得到的结果相同。这就是sparse_softmax_cross_entropy_with_logits函数的计算过程,tf.contrib.legacy_seq2seq.sequence_loss_by_example函数的计算过程就是在其内部的每个时间步中调用sparse_softmax_cross_entropy_with_logits函数即可。
4 小结
本文通过tensorflow官方提供的基于LSTM的语言模型ptb_word_lm.py例子中的部分代码,对tf.contrib.legacy_seq2seq.sequence_loss_by_example函数的计算过程进行了简单的介绍,这其中的理论知识可以查看前文中链接到的哪些博文,这里只是纯介绍计算过程,因为这也是我最近遇到的问题。我也不知道有没有错,如果文中有写错或者理解错误的地方,请大家及时联系我纠正,谢谢!
参考文献(时间仓促,就没单独整理了)
【1】前文提到的所有链接
【2】tensorflow官方文档以及官方代码