使用Hugging Face提供的pytorch接口来使用bert,这篇主要记录下BertTokenizer中英文分词情况。
1、准备
pip install pytorch-pretrained-bert
2、分词思路
BertTokenizer 是用WordPiece模型创建的。这个模型使用贪心法创建了一个固定大小的词汇表,其中包含单个字符、子单词和最适合我们的语言数据的单词。由于我们的BERT tokenizer模型的词汇量限制大小为30,000,因此,用WordPiece模型生成一个包含所有英语字符的词汇表,再加上该模型所训练的英语语料库中发现的~30,000个最常见的单词和子单词。这个词汇表包含以下一些东西:
- 整个单词
- 出现在单词前面或单独出现的子单词
- 不在单词前面的子单词,在前面加上“##”来表示这种情况
- 单个字符
要在此模型下对单词进行记号化,tokenizer首先检查整个单词是否在词汇表中。如果没有,则尝试将单词分解为词汇表中包含的尽可能大的子单词,最后将单词分解为单个字符。注意,由于这个原因,我们总是可以将一个单词表示为至少是它的单个字符的集合。
因此,不是将词汇表中的单词分配给诸如“OOV”或“UNK”之类的全集令牌,而是将词汇表中没有的单词分解为子单词和字符令牌,然后我们可以为它们生成嵌入。
例如,对于词汇表中没有的单词embedding,我们没有将“embeddings”和词汇表之外的每个单词分配给一个重载的未知词汇表标记,而是将其拆分为子单词标记[‘ em ‘、’ ##bed ‘、’ ##ding ‘、’ ##s ‘],这些标记将保留原单词的一些上下文含义。我们甚至可以平均这些子单词的嵌入向量来为原始单词生成一个近似的向量。
3、简述分词源代码
BERT的分词是Python的代码,打开tokenization.py就能看到这个文件里的代码还是很容易理解的。主要有两类,一类是功能性方法,另一类是不同的分词方法类。
3.1 功能性方法
主要包含了5个功能方法:
load_vocab(vocab_file) :主要是加载词汇表,构建一个有序字典,并建立词汇和id之间的映射关系
whitespace_tokenize(text):将给定文本按照空格进行分词。
_is_punctuation(char):判断给定字符是否是标点符号;
_is_control(char):判断给定的字符是否是转义字符;
_is_whitespace(char):判断给定的支付是否是空白符;
3.2 三种分词方法
(1)最常用的分词方法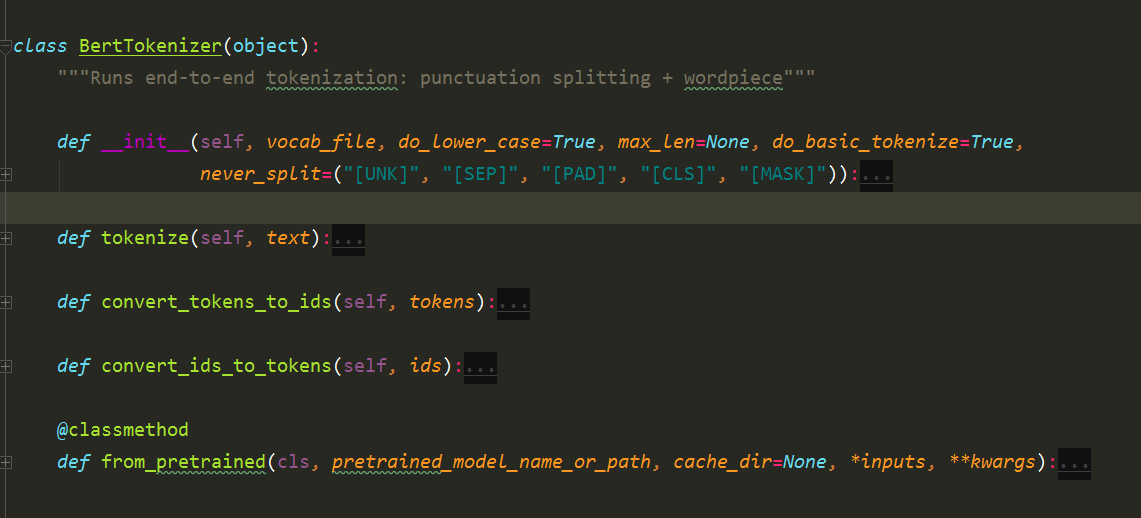
构造函数需要传入参数词典vocab_file和do_lower_case,函数首先调用load_vocab加载词典,建立词到id的映射关系。接下来是构造BasicTokenizer和WordpieceTokenizer。前者是根据空格等进行普通的分词,而后者会把前者的结果再细粒度的切分为WordPiece。
tokenize函数实现分词,它先调用BasicTokenizer进行分词,接着调用WordpieceTokenizer把前者的结果再做细粒度切分。
(2)BasicTokenizer
(3)WordpieceTokenizer
后面这两种分词方法不做详细介绍,需要深入了解的可以直接查看源代码。
4、简单用法demo
首先要下载预训练好的模型,然后放在指定目录下: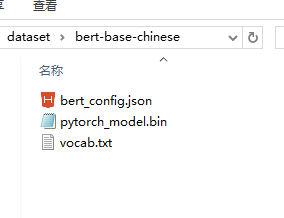
from pytorch-pretrained-bert.tokenization import BertTokenizer
# 加载bert分词器
tokenizer = BertTokenizer.from_pretrained('./bert-base-chinese', do_lower_case=True)
print(tokenizer.tokenize("我要去看北京的天安门"))
print(tokenizer.tokenize("I will go to BeiJing"))
分词结果(中文是将文本分成单个字,而不是词语):
['我', '要', '去', '看', '北', '京', '的', '天', '安', '门']
['i', 'will', 'go', 'to', 'be', '##i', '##jing']



