之前配置过环境,然后过段时间就忘了,最近又在折腾机器,重新配置环境,跟着网上的教程来,发现走了很多坑,所以记录下。
我的账号是带sudo权限的非root用户,不带sudo权限应该也是可以的。
1、准备
前期准备主要是版本对应上:
cuda和驱动程序
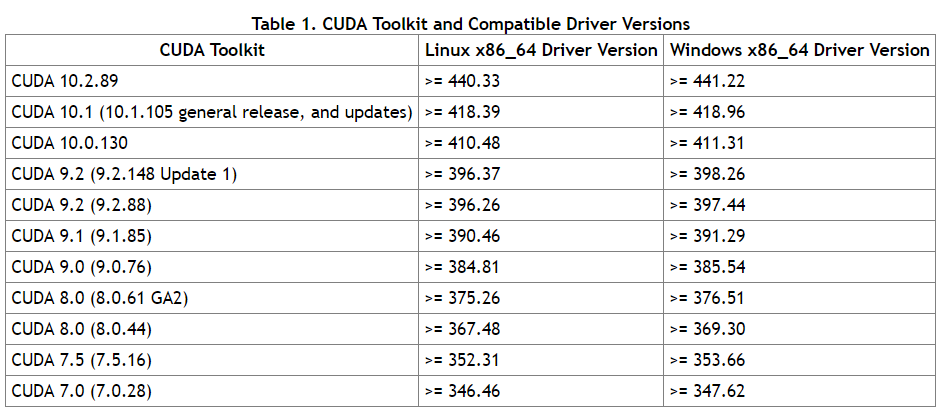
cuda和cudnn
具体对应关系参照:https://blog.csdn.net/omodao1/article/details/83241074
cuda和pytorch
前往pytorch官网查看版本的对应关系。https://pytorch.org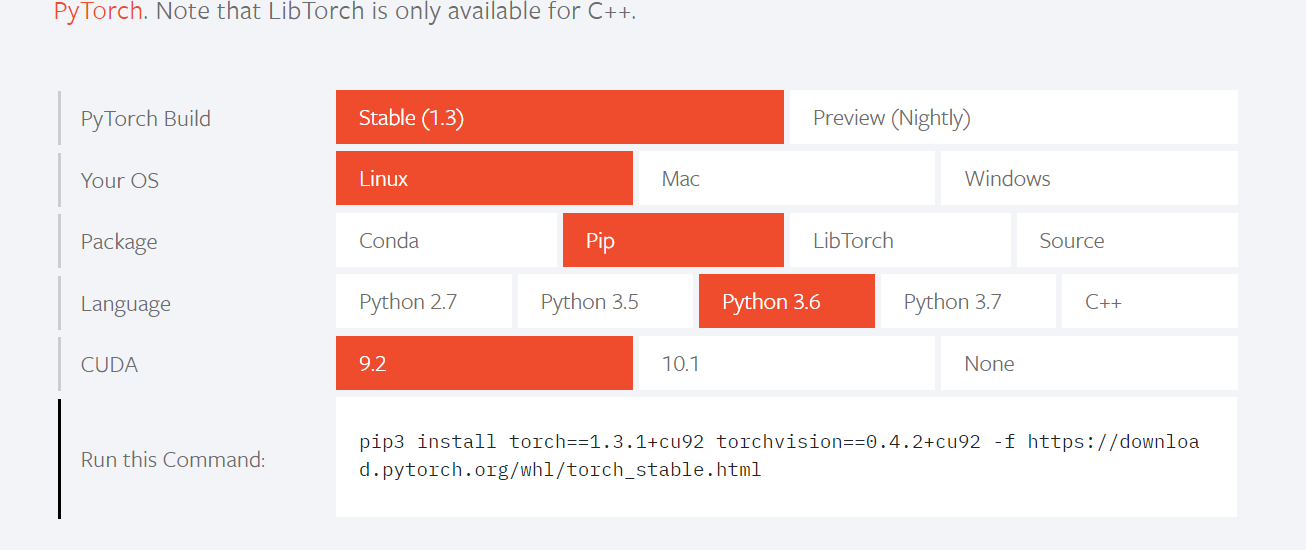
2、安装
2.1 安装驱动程序
这个驱动程序其实可以在装cuda的时候装,也可以单独安装。由于原来的驱动程序和现在的cuda版本对应不上,所以我是把原来的驱动程序卸载了,在安装cuda时重新安装的,单独安装方法可以在网上搜下,但是一定要记住版本对应上(驱动程序和显卡型号也要对应上)。
2.2 安装cuda
去官网下载安装包,我的系统是Ubuntu,所以下载的是cuda_9.0.176_384.81_linux.run。
然后在同级目录下执行:
bash cuda_9.0.176_384.81_linux.run
先后会遇到各种配置问题:
- 是否accept? accept
- driver? 这个根据自己的情况来,如果是已经安装了则no,如果已经安装了,想重新安装,需要将之前的卸载了再安装,此时yes
- openGL? 好像是如果安装driver时才有的选项,yes
- nvidia-xconfig? 这里我选择的no
- cuda tookit? yes
- cuda安装路径:这个根据自己的需要来看是否修改
- cuda samples ? yes
- samples 路径:根据情况修改
这个步骤没出问题的话,基本上就是可以了的,网上有些教程里修改了cuda的环境变量,但是我没有修改,却可以使用,不知道是不是版本的原因?
测试是否安装成功:
(1)看nvcc版本nvcc —version
(2)看驱动能不能用nvidia-smi
(3)进入到samples文件夹在用户目录下或者/usr/local/cuda/samples下都有,进入1_Utilities/deviceQuery中,make 然后运行./deviceQuery,会输出一堆信息,最后是PASS,之前都对。
2.3 安装cudnn
去官网下载,要注册的。https://developer.nvidia.com/rdp/cudnn-download。选择cuDNN v5.1 Library for linux下载之后解压,下载下来之后是.tgz后缀,然后用tar -xvf解压即可。然后把lib和include拷贝到cuda对应的目录下:
sudo cp cuda/include/cudnn.h /usr/local/cuda/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
网上的教程说这里还要修改文件权限和建立链接,我没有弄,结果还是正确的。
2.4 安装python、pytorch
这部分就相对来说简单很多了,可以直接参考官网教程:https://pytorch.org
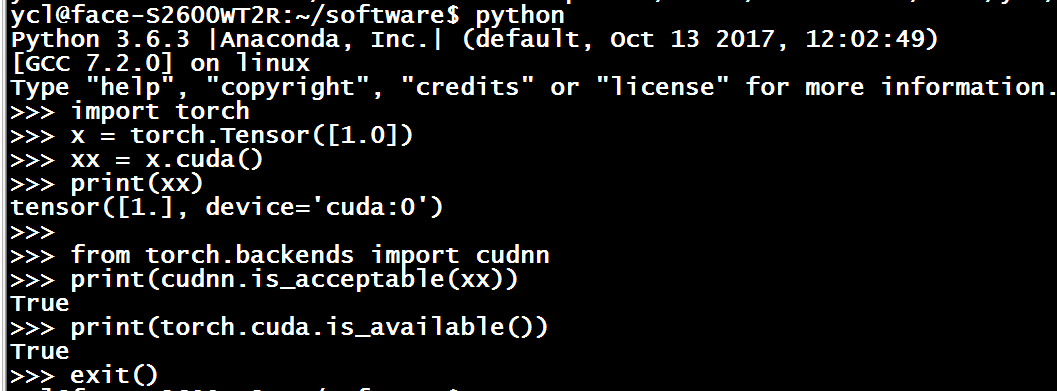
3 测试pytorch的gpu环境是否安装好
# CUDA TEST
import torch
x = torch.Tensor([1.0])
xx = x.cuda()
print(xx)
# cuDNN test
from torch.backends import cudnn
print(cudnn.is_acceptable(xx))
print(torch.cuda.is_available())
我的输出结果: