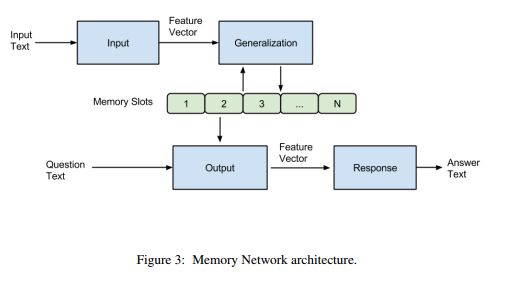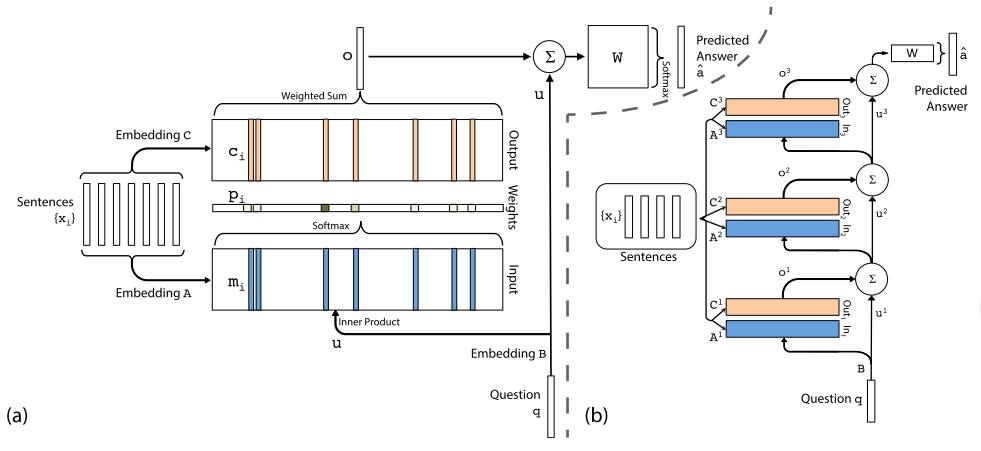
1 背景(1)在记忆网络中,主要由4个模块组成:I、G、O、R,前面也提到I和G模块其实并没有进行多复杂的操作,只是将原始文本进行向量表示后直接存储在记忆槽中。而主要工作集中在O和R模块,O用来选择与问题相关的记忆,R用来回答,而这两部分都
2018-11-17